

 153310/29
153310/29

OpenAI昨天晚上9点,公布了一个消息。
这个事,影响还蛮大的,基本代表着,OpenAI在开始准备上市了。
然后,奥特曼也非常临时的宣布了重组的消息,以及,北京时间凌晨1点半,开始直播。
整体直播了将近1个小时,一直到凌晨2点半。
这次能感觉到,奥特曼和现任首席科学家Jacob几乎没啥准备,很多时候真的就是临场发挥,然后看评论,回答问题,两人都显得还挺疲惫的。
我也通宵整理了直播中间提到的所有信息,再结合OpenAI最近的一些动向,内容其实还是挺多的。
不过,在说直播之前,还是得说一下这次整体的引子,也是一切的源头。
就是OpenAI,历经将近一年,终于完成了重组。
这其实是2024年12月他们提的一项重组计划,那时候,OpenAI试图将有限盈利子公司从非营利母公司的直接控制中释放出来,让非营利组织将出售控制权换取大笔股权,转而成为主要股东和慈善实体,从而使OpenAI转变为一个可以自由增发股票、IPO上市的公司。
对OpenAI历史有了解的朋友可能都知道,OpenAI其实是纯粹的非营利非机构起家,2015年的时候奥特曼和马斯克等巨佬们一起创立的,目标是,“确保通用人工智能(AGI)造福全人类”。
那时候,强调不以盈利为约束,不指望OpenAI能挣钱,以便于做长期、成本高的基础研究,避免利润驱动,以公益为核心目标。
当时确实有很强的历史背景和理想主义色彩,2014年深度学习大行其道,Google又收购了极度牛逼的DeepMind,一下子让马斯克他们急了。
后来呢,随着研究的推进,OpenAI逐渐发现,到仅靠非营利模式(也就是捐款和赞助),难以支撑迈向AGI所需的巨额投入。
特别是2017到2018年期间,OpenAI在训练Dota 2游戏AI和其他大模型上消耗了巨额算力,高昂的算力成本让OpenAI高层意识到不对劲了:
实现AGI可能需要的资金将超过任何非营利组织历史上筹集过的规模。
当时OpenAI的联合创始人Ilya也说:“我们意识到,作为一个纯非营利组织,我们的筹款能力已经达到上限”。所以,为了解决资金和人才激励问题,OpenAI开始寻求结构转型。
2019年3月11号,OpenAI宣布成立一个“有上限盈利”的子公司OpenAI LP(有限合伙制)。大概就是在保留非营利母公司控制权的前提下,引入盈利机制以吸引投资。根据设计,外部投资者和员工可持有子公司的股权,但投资回报率被封顶在100倍,超过上限的任何超额利润都将归属于OpenAI的非营利实体,用于公益目的。
这所以这么诡异的设一个上限,其实就是纯粹的折中手段,即以明确的盈利上限来约束投资者的贪欲,确保研究方向不因逐利而偏离初衷。
所以,2019年的调整形成了“双层实体”结构,原有的非营利组织(OpenAI Inc.)成为控股母公司,100%控制新成立的营利实体(OpenAI LP)。
事实证明,引入有限盈利结构很快为OpenAI换来了急需的资金。2019年7月,微软宣布向OpenAI投资10亿美元,并成为OpenAI的重要战略合作伙伴。
从那时候起,一些AI研究者和业内人士其实就已经在批评OpenAI不再像名字那样真的OpenAI,而是变成Close AI了。
当时2019年2月OpenAI发布GPT-2模型时,就因为担心滥用只开源了阉割版模型,被一通骂。等到GPT-3在2020年问世时,OpenAI甚至完全放弃了开源,而是通过付费API向大家提供模型服务,又是被一通骂。
很多人都在说,这跟OpenAI最初“开放共享”的承诺是完全背离的。
就这样,一直持续到了2024年12月,虽然2019到2024这五年里,OpenAI又有一通乱七八糟的风波,但是ChatGPT2022年11月亮相的那一刻,他们就成了AI圈最亮眼的明星。
再然后,就是最开始所说的,OpenAI更进一步,想完全出售非营利组织的控制权换取大笔股权,让OpenAI这家公司,以及背后AGI的开发和部署控制权从非营利慈善机构转移到营利性企业。
当时,这一计划引发了巨大争议,一批巨佬和OpenAI的前员工们,当时联名发表公开信《Not For Private Gain》向加州和特拉华州检察长喊话,要求阻止OpenAI进一步的商业化重组,认为放弃非营利控制权将使公司背离使命。
最终,OpenAI在压力下调整方案,决定保留非营利的控制权,但对架构进行重大简化和资本重组,以进一步提高融资能力,毕竟,之前的100盈利上限限制还是太大了。
在提出重组将近一年以后,终于,被批准,新结构出炉。
也就是今天的这条公告。
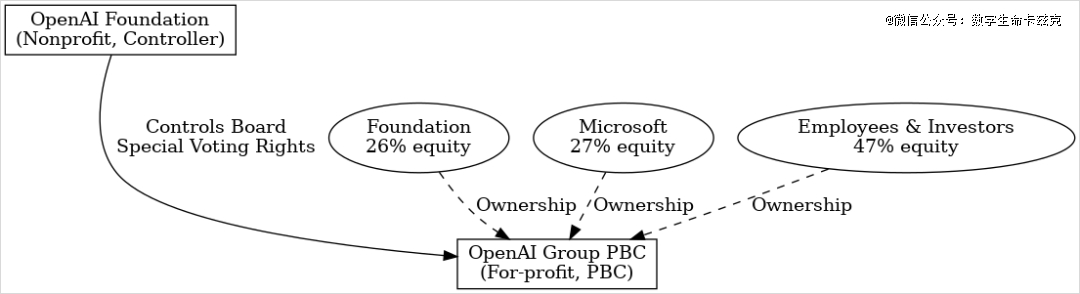
非营利主体更名为“OpenAI Foundation”(开放AI基金会),一家新的营利公司OpenAI Group PBC。这里PBC指的是“公共利益公司”(Public Benefit Corporation),一种法律形态,要求公司在追求利润的同时必须考虑既定的公益使命。
新结构的特点大概可以这么概括:
1.非营利基金会持有26%股权并掌握控制权。OpenAI Foundation作为母公司,拥有OpenAI Group PBC约26%的普通股股权,根据目前OpenAI的估值,大概是1,300亿美元,同时,基金会通过特别表决权完全控制着PBC的董事会任免权,可以随时更换公司董事。
2.OpenAI Group转换为PBC公司,准备融资上市。原来的有限合伙子公司(OpenAI LP)经过重组,变身为特拉华州注册的OpenAI Group PBC。这家营利公司接纳了新的外部股东和大量资本,公司估值被推高到了恐怖的5000亿美元。
微软在新结构下的持股比例约为27%,剩余约47%的股份由OpenAI的员工和早期投资者持有。至此,OpenAI Group PBC也成为全球估值最高的未上市公司之一,而作为PBC,公司拥有了发行股票、日后IPO上市的资格。
重组消息发布后,微软股价开盘就涨了4%,虽然后面又跌了一点,但市值也突破了4万亿美元。
目前OpenAI的新结构图如下。
接下来的环节,就到了1小时的直播了。
开头其实就是把我上面说的这些东西,有全部说了一遍,我就不赘述了。
除了上面这些已经讲过的,我个人觉得,还是有1个他们讲的比较值得写出来的点,以及最后真正的Q&A环节(这是OpenAI的*次Q&A),这个环节信息量会更多一些,也跟大家息息相关。
先说这个稍微值得关注的点:
AGI的核心影响是加速科学发现。
他们认为,这可能是 AI 发展的最重要长期影响之一,也会从根本上改变新技术诞生的节奏。
在OpenAI内部目标里,到2026年9月,他们可能会有一个“研究实习生级的AI助手”(PS:这里的研究实习生指的是可以在OpenAI里当研究员的实习生级别,不是一个普通的研究生),到2028年3月,差不多是GPT-4发布后第五年,会有一个货真价实的全自动AI研究员。
不过OpenAI画的饼已经够多了,这个我觉得,听听就得了,总感觉,这玩意也是给今晚在听直播的资本画饼。。。
然后就是喜闻乐见的Q&A环节,也是OpenAI有史以来*次做。
很多问题我都觉得挺有趣的,OpenAI被拷打的汗流浃背,我就直接放原问题和他们的原回答,尽量不改变原意了。
Q1:你们一边警告技术会让人上瘾,一边又让Sora模仿TikTok,ChatGPT还可能加广告。你们怎么说一套做一套?
答:我们确实很担心。但你必须看我们的行动。比如,Sora要是变得超让人上瘾,我们会砍掉它。我们会犯错,但希望能犯点“新错误”,而不是重复过去的坑。我们的目标是为用户的长期福祉而优化,而不只看短期数据。
Q2:能*保留GPT-4吗?我们成年人不需要你们管。
答:我们暂时没有下线GPT-4o的计划,我们知道大家喜欢它。但它对未成年人确实不太健康。我们希望成年人能在合规前提下自己做选择。
Q3:你们的“安全路由”(自动切换模型)太家长式了,剥夺了成年人的选择权,什么时候改?
答:我承认我们上次处理得很糟。事实是,GPT-4o确实对一些精神脆弱的用户造成了伤害。我们必须保护未成年人和这些脆弱的成年人。等我们上了年龄验证(age verification) 功能后,成年用户会获得多得多的自由。
Q4:12月的“成人模式”到底什么时候来?写点东西老是被拦。
答:不确定12月的具体哪天。但目标很明确:在创意写作这类场景下,会比以前的限制宽松得多。我们知道现在的过滤器有多烦人,会尽力修复它。
Q5:你们的安全理念,难道就建立在“骗用户在用哪个模型”的基础上吗?
答:这事我们确实搞砸了。我们的初衷是:在年龄验证功能上线前,如果系统发现4o的某些行为可能对用户造成伤害,就自动把你切换到一个更安全的模型上。4o就是这么个挑战,有人爱它,但它也确实伤害了另一些人。
Q6:我爱GPT-4.5的写作能力,它会消失吗?
答:我们很快会有比4.5在写作上好得多的模型。我们内部已经不觉得4.5那么好了,我预计明年肯定会有更好的。
Q7:ChatGPT会出一个专注个人情感连接的版本吗?
答:当然会。AI能帮人们处理个人困境、过上更好的生活,这深深触动了我们。这正是我们做这件事的意义所在。
Q8:12月的成人模式更新会明确你们对“人机情感”的立场吗?
答:我们没什么“官方立场”。你想怎么用就怎么用。如果你从AI那获得了情感支持或友谊,并觉得这对你很重要,那我们觉得这太棒了。我们只要求模型必须诚实,不能假装自己是人。
Q9:你们既然做了高情商模型,为什么又批评用户用它来获取情感支持?
答:我们不批评,我们认为这是件好事。真正的问题是,同一个模型可能被用来助长精神脆弱用户的幻想。我们希望用户是清醒地、有意图地在使用它,而不是被模型“欺骗”。
Q10:AGI(通用人工智能)什么时候实现?
答 (Jakup):我觉得,我们现在就处在AGI发生的过渡期。它更像是一个连续的过程,而不是一个“奇点”。
答 (Sam):AGI这个词被滥用了。我们觉得,与其争论定义,不如定个具体目标,比如“到2028年3月,实现一个真正的自动化AI研究员”。
Q11:你们的内部模型比公开发布的*多少?
答:我们预计未来几个月会进展神速。但我们并没有“藏着”什么超级大杀器。我们是先把很多很牛的“零件”开发出来,等时机成熟了再把它们组装在一起。我们预计一年内会有一次极其重要的能力飞跃。
Q12:会开源GPT-4这种旧模型吗?
答:也许有一天会当“博物馆文物”开放吧。但说实话,GPT-4原版作为开源模型没啥用,又大又笨。我们更倾向于做个能力更强但体积很小的模型开源,那才真的有用。
Q13:你们会承认新模型比旧的差吗?
答:我相信,对你的特定使用场景来说,新模型确实更差了。整体而言,我们认为它对大多数用户是更好的。但我们确实从这次升级中学到了教训。
Q14:想象力是否成了模型优化的牺牲品?
答:在迭代中确实可能存在权衡,但这是暂时的。我的期望是AI最终让人类更有创造力。当然,我们也看到了两种极端:一种人思路被打开了,另一种人开始“外包”自己的思考。我们显然希望是前者。
Q15:GPT-6什么时候出?
答:我不知道具体什么时候我们会管它叫GPT-6。但我们想传达的信息是:从现在起的六个月内,甚至更早,我们预计模型能力会迎来又一次巨大飞跃。
Q16:OpenAI会和Anthropic、Gemini(谷歌)这些对手合作吗?
答:在安全方面,这将越来越重要。事实上,我们已经和谷歌、Anthropic等实验室的研究人员,在安全规范方面展开了初步合作。
Q17:为什么OpenAI能给免费版用户开放这么多功能?
答:因为我们降低成本的速度非常快。在过去几年,“智能”的价格大概每年下降40倍。GPT-3级别的模型现在基本等于白送。我们的目标就是把智能的成本降下来,并继续把*的技术放进免费版。
Q18:ChatGPT是你们的*产品,还是只是一个前奏?
答:聊天是个好界面,但不是*的。AI真正的遗产,是它能真正推动科学。我更希望它未来能成为一个“环境化、始终在场”的伙伴,能“观察”你的生活并主动提供帮助。
Q19:Windows版的ChatGPT啥时候出?
答:没准信,我猜还得几个月吧。
Q20:AI导致的大规模失业什么时候会发生?
答:我认为现在已经到了一个临界点。阻止AI取代脑力工作的,已经不是智力本身,而更多是系统集成和交互界面的问题。脑力工作的大规模自动化会在未来几年发生。
Q21:当AI自动化了一切,人类的“意义”在哪?
答 (Jakup):这是个很哲学的问题。我预计,高层次的目标设定(High-level goal setting),比如决定我们要追求什么,这部分会保留在人类手中。我想很多人会从中获得意义。
Q22:还打算IPO(上市)吗?
答:目前没具体计划。但考虑到我们(未来)对资金的需求,IPO是最有可能的路径。
Q23:要支撑1.4万亿的投资,你们需要多少收入?
答:我们最终需要达到每年数千亿美元的收入。B端(企业)和C端(消费者)都会是巨大的收入来源。这还没算上AI未来真正开始“发现科学”能带来的价值。
这次的Q&A大概就是这些,信息量还是有一些的,也直面回答了一些之前让用户愤怒的路由问题等等。
现在,基本就坐等12月ChatGPT的成人模式更新了,只能说在他们更新之前,我的主力模型,可能还是Gemini 2.5 Pro。









